
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 요리책
- JSON encoding
- heap
- 요리책 운영체제
- Java
- JSON UTF-8
- CloudFunction
- 브라우저 JSON 인코딩
- 브라우저 JSON encoding
- chapter7
- GCP PubSub
- 물리 메모리 관리
- Algorithm
- Python
- github 403
- 연습문제
- PubSub
- codingtest
- 알고리즘
- 네트워크와 분산 시스템
- 스프링 APPLICATION_JSON_UTF8
- 코딩테스트
- chapter8
- github personal access token
- github access token
- 운영체제
- 문제 풀이
- 가상 메모리 기초
- github push 403
- CPU 스케줄링
- Today
- Total
이도(李裪)
자바 문자열 해시코드 - Java String hash code 본문
String의 hash code에 대해 조사해보았습니다
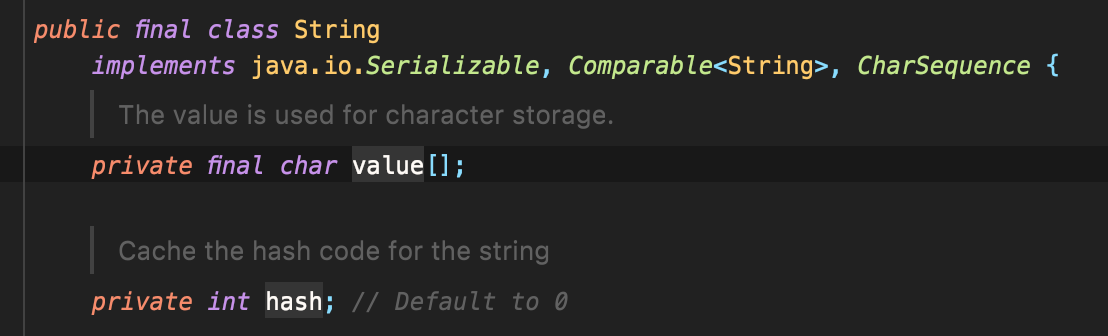
String.hashCode() 내부 구현 코드
String Class에서
"String" 값은 `value` 변수에 저장하고 있습니다
해시 코드 값은 `hash`에 저장하고 있습니다
(그래서 hashCode() 함수에서 != 0 이라면 기존에 가지고 hash 멤버 변수 반환이 가능합니다)
우선 openjdk 11과 openjdk 1.8의 구현의 아이디어는 동일하나 내부 구현이 조금은 다릅니다
공부를 위해서 좀 더 직관적인 openjdk 1.8 기준으로 공부했습니다


해시코드 계산방법
hashCode() 함수를 살펴보면
- 멤버변수 hash가 있으면 즉, hash code를 계산한 적이 있어서 int 기본값인 0이 아니면 멤버변수 hash를 반환합니다
- value[]가 final로 선언되어있어서 immutable 입니다. value가 한 번 대입되면 변하지 않기 때문에 hash 값이 변하지 않을 수 있습니다
- 계산한 적이 없으면, 문자열(string)을 앞에서부터 한 자씩(char) 읽으면서 ascii code로 변환해서 처리를 합니다.
- 기존까지 계산한 값은 31을 곱하고 새로운 문자는 ascii code의 숫자로 변환해서 숫자로 더합니다
내부 소스코드에서 break point 걸고 컴파일 모드로 실행하니 기대한 것처럼 실행이 안 되서 코드를 복사해서 컴파일 모드로 실행한 모습입니다

왜 31일까 13, 17, 33, 51 등 다른 수들은??
소수이면서 홀수인 31을 선택한 이유가 무엇인지 궁금했습니다.
Effective Java 책에 나오는 내용입니다
31은 소수이면서 홀수이기 때문에 선택된 값이다. 만일 그 값이 짝수였고 곱셈 결과가 오버플로되었다면 정보는 사라졌을 것이다. 2로 곱하는 것은 비트를 왼쪽으로 shift하는 것과 같기 때문이다. 소수를 사용하는 이점은 그다지 분명하지 않지만 전통적으로 널리 사용된다. 31의 좋은 점은 곱셈을 시프트와 뺄셈의 조합으로 바꾸면 더 좋은 성능을 낼 수 있다는 것이다(31 * i는 (i << 5) - i 와 같다). 최신 VM은 이런 최적화를 자동으로 실행한다.
[31은 퍼포먼스 측면에서 이점이 있습니다]
관련된 글들을 찾아보았을 때 퍼포먼스를 고려한 것으로 생각이 듭니다
31은 32 - 1 입니다. 32 * num 는 bit shift 연산을 이용해서 num << 5 입니다
그래서 31 * num는 num << 5 - num 입니다
31을 곱했을 때 compiler가 최적화를 실행해줍니다
[짝수를 사용하지 않는 이유]
짝수를 사용하지 않은 이유는 곱셈의 결과에서 overflow 발생하였을 때 정보의 손실 때문입니다
[소수를 사용하는 이유]
마지막으로 33, 51과 같은 홀수를 사용해도 되는데 소수를 사용한 이유는 알고리즘에서 소수가 도움이 될거라는 수학적인 믿음(미신)이 있는 거 같습니다
정리하면, bit shift 연산을 사용할 수 있기 때문에 (1) 퍼포먼스 측면, (2) 홀수이기 때문에 정보의 손실이 없고, (3) 수학적 믿음으로 31이 선택되었다고 생각합니다
해시 코드의 중복 문제
String의 hash code 계산하는 로직을 보면 충돌이 있을 거 같다라는 생각이 들었습니다.
해시 함수도 낮지만 충돌가능성이 있는데 위의 로직은 충돌이 충분히 일어날 것처럼 보입니다.
String a = "Aa";
String b = "BB";
System.out.println("a.hashCode() = " + hashCode(a.toCharArray())); // 2112
System.out.println("b.hashCode() = " + hashCode(b.toCharArray())); // 2112
String string1 = "Siblings";
String string2 = "Teheran";
System.out.println("string1.hashCode() = " + string1.hashCode()); // 231609873
System.out.println("string2.hashCode() = " + string2.hashCode()); // 231609873
String x = "Z@S.ME";
String y = "Z@RN.E";
System.out.println("x.hashCode() = " + hashCode(x.toCharArray())); // -1656719047
System.out.println("y.hashCode() = " + hashCode(y.toCharArray())); // -1656719047
구글링을 조금만 해보면 충돌 문자열을 쉽게 찾을 수 있습니다.
해시 코드는 Java Map에서 key를 판별하는 데 사용이 되는데 이를 어떻게 해결하는 지 이어서 찾아보았습니다.
Java HashMap에서 해시 중복 문제
Java HashMap 내부 구현에서 hash code를 사용할텐데 이 문제를 해시가 중복되는 문제를 어떻게 해결하는 지 궁금했습니다
import java.util.HashMap;
public class MapTest {
public static void main(String[] args) {
HashMap<String, Integer> hashMap = new HashMap<>();
hashMap.put("Siblings", 1);
hashMap.put("Teheran", 2);
System.out.println(hashMap); // {Siblings=1, Teheran=2}
}
}위의 결과값을 보면 hash code가 중복이 일어나도 내부적으로 처리하는 게 있다는 것을 알 수 있습니다
자료구조/알고리즘 공부할 때 해시 충돌날 때 같은 해시 값에 대해서 value값들을 ArrayList나 LinkedList로 저장하는 게 기억이나는 데 아마 그럴 거 같습니다
아니면 내부적으로 다른 해시 방법을 사용해서 처리하고 있을수도 있습니다
(결론은 내부적으로 해시 처리를 한 번 더 하고 그래도 중복이 있다면 value 값을 TreeNode에 체이닝해서 이어서 저장합니다)
궁금하니 내부 구현 코드를 보았습니다
1. put 함수
`put()` 함수는 기존의 값이 있으면 덮어쓰도록 (evict, 추방하도록) 구현되어있고 반환값으로 기존 값을 반환합니다
`put()`은 내부적으로 `putVal()` 함수를 호출하고 있습니다 그 중 첫 번째 인자값에 `hash()` 함수를 호출해서 넣고 있습니다
2. hash 함수
object의 hashCode()를 호출해서 가져오고 16비트를 오른쪽으로 이동시킨 뒤에 XOR로 마스킹처리 합니다

아까 해시코드가 중복이 났던 것을 가지고 이 함수에서 중복이 안 나는 지 확인해보았습니다
public class MapTest {
public static void main(String[] args) {
String sibiling = "Siblings";
String teheran = "Teheran";
int h1 = sibiling.hashCode();
int h2 = teheran.hashCode();
System.out.println(Integer.toBinaryString(h1));
System.out.println(Integer.toBinaryString(h1 >>> 16));
System.out.println(Integer.toBinaryString((h1 ^ (h1 >>> 16))));
/*
* 1101 1100 1110 0001 0110 0001 0001
* 0000 0000 0000 0000 1101 1100 1110
* ----------------------------------
* 1101 1100 1110 0001 1011 1101 1111
* */
System.out.println(h1 ^ (h1 >>> 16)); // 231611359
System.out.println(h2 ^ (h2 >>> 16)); // 231611359
}
}HashMap 내부에서 사용하는 hash 함수를 적용해보아도 중복이 납니다.
해시코드가 동일하다면 비트를 16자리 밀고 XOR 마스킹 해도 당연히 동일할 수 밖에 없습니다
기본적으로 해시코드가 달라야지 달라지는 구조입니다.
(hash code만 사용하면 되지 이렇게 사용한 이유가 궁금했는데 주석으로 잘 설명이 되어있습니다 - 이 부분은 차후에 더 공부해보도록 하겠습니다)
3. putVal 함수

내부가 굉장히 복잡해 보입니다 코드가 정말 깁니다
Naver D2 - HashMap 글에 자세히 설명되어 있습니다 (https://d2.naver.com/helloworld/831311)
저는 대략적으로 제가 필요한 부분만 확인해보겠습니다
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 해시 테이블이 초기화되어 있지 않으면 초기화 합니다
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 테이블에서 중복된 해시 값이 없으면 노드를 만들어서 넣습니다 (해시 중복이 없는 경우)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
// * 해시 중복이 있는 경우
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 중복된 해시 값에 대해 다른 value 값을 넣습니다
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
Java HashMap에서 put() 함수는 내부적으로 hash() 함수를 한번 더 호출해서 해시를 만들어서 쓰고 putVal() 함수가 실제로 동작하는 내부 구현입니다
putVal()에서 중복된 해시 값에 다른 value 값이 있으면 chaining해서 넣는 것을 알 수 있습니다
Reference
https://johngrib.github.io/wiki/Object-hashCode/#31이-소수이면서-홀수이기-때문이다
java.lang.Object .hashCode 메소드
johngrib.github.io
https://nesoy.github.io/articles/2018-06/Java-equals-hashcode
Java equals()와 hashCode()에 대해
nesoy.github.io
추가로 공부할 자료
https://d2.naver.com/helloworld/831311
'개발' 카테고리의 다른 글
| GitHub 403 Error. Access Token 설정 방법 (0) | 2021.08.14 |
|---|---|
| 브라우저별 JSON default encoding (0) | 2021.08.14 |
| Java Memory Management, Primitive Type And Reference Type, String Pool (0) | 2021.08.01 |
| HTTP GET method with payload body (0) | 2021.07.29 |
| [알고리즘] 문자열 압축 Python (0) | 2021.07.25 |



